Nas escolas de todo o mundo, as crianças digitam um número em sua calculadora de LCD, viram-no de cabeça para baixo e caem na gargalhada depois de criar a palavra 'Boobies'. Obviamente, essa é a palavra mais popular, mas há muitas outras que podem ser produzidas.
No entanto, todas as palavras devem ter menos de 10 letras (no entanto, o dicionário contém palavras maiores que isso, portanto, você deve executar um filtro no seu programa). Neste dicionário, existem algumas palavras em maiúsculas, portanto, converta todas as palavras em minúsculas.
Usando um dicionário do idioma inglês, crie uma lista de números que podem ser digitados em uma calculadora LCD e faça uma palavra. Como em todas as perguntas sobre código de golfe, o programa mais curto para concluir esta tarefa vence.
Para meus testes, usei a lista de palavras UNIX, reunida digitando:
ln -s /usr/dict/words w.txt
Ou, alternativamente, obtenha-o aqui .
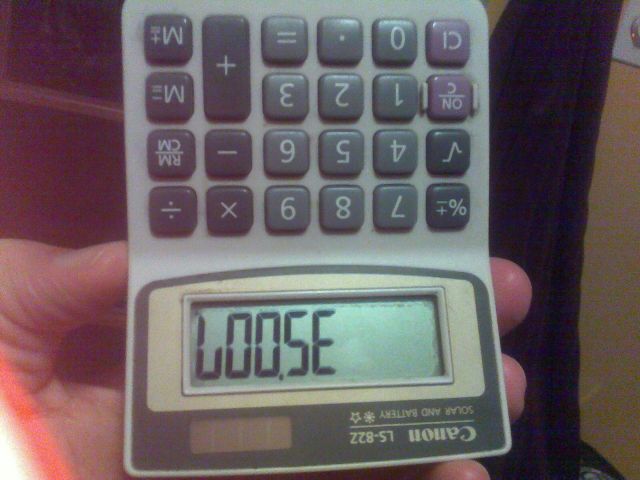
Por exemplo, a imagem acima foi criada digitando o número 35007na calculadora e virando-o de cabeça para baixo.
As letras e seus respectivos números:
- b :
8 - g :
6 - l :
7 - i :
1 - o :
0 - s :
5 - z :
2 - h :
4 - e :
3
Observe que, se o número começar com zero, será necessário um ponto decimal depois desse zero. O número não deve começar com um ponto decimal.
Eu acho que esse é o código da MartinBüttner, só queria creditar você por ele :)
/* Configuration */
var QUESTION_ID = 51871; // Obtain this from the url
// It will be like http://XYZ.stackexchange.com/questions/QUESTION_ID/... on any question page
var ANSWER_FILTER = "!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe";
/* App */
var answers = [], page = 1;
function answersUrl(index) {
return "http://api.stackexchange.com/2.2/questions/" + QUESTION_ID + "/answers?page=" + index + "&pagesize=100&order=desc&sort=creation&site=codegolf&filter=" + ANSWER_FILTER;
}
function getAnswers() {
jQuery.ajax({
url: answersUrl(page++),
method: "get",
dataType: "jsonp",
crossDomain: true,
success: function (data) {
answers.push.apply(answers, data.items);
if (data.has_more) getAnswers();
else process();
}
});
}
getAnswers();
var SIZE_REG = /\d+(?=[^\d&]*(?:<(?:s>[^&]*<\/s>|[^&]+>)[^\d&]*)*$)/;
var NUMBER_REG = /\d+/;
var LANGUAGE_REG = /^#*\s*([^,]+)/;
function shouldHaveHeading(a) {
var pass = false;
var lines = a.body_markdown.split("\n");
try {
pass |= /^#/.test(a.body_markdown);
pass |= ["-", "="]
.indexOf(lines[1][0]) > -1;
pass &= LANGUAGE_REG.test(a.body_markdown);
} catch (ex) {}
return pass;
}
function shouldHaveScore(a) {
var pass = false;
try {
pass |= SIZE_REG.test(a.body_markdown.split("\n")[0]);
} catch (ex) {}
return pass;
}
function getAuthorName(a) {
return a.owner.display_name;
}
function process() {
answers = answers.filter(shouldHaveScore)
.filter(shouldHaveHeading);
answers.sort(function (a, b) {
var aB = +(a.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0],
bB = +(b.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0];
return aB - bB
});
var languages = {};
var place = 1;
var lastSize = null;
var lastPlace = 1;
answers.forEach(function (a) {
var headline = a.body_markdown.split("\n")[0];
//console.log(a);
var answer = jQuery("#answer-template").html();
var num = headline.match(NUMBER_REG)[0];
var size = (headline.match(SIZE_REG)||[0])[0];
var language = headline.match(LANGUAGE_REG)[1];
var user = getAuthorName(a);
if (size != lastSize)
lastPlace = place;
lastSize = size;
++place;
answer = answer.replace("{{PLACE}}", lastPlace + ".")
.replace("{{NAME}}", user)
.replace("{{LANGUAGE}}", language)
.replace("{{SIZE}}", size)
.replace("{{LINK}}", a.share_link);
answer = jQuery(answer)
jQuery("#answers").append(answer);
languages[language] = languages[language] || {lang: language, user: user, size: size, link: a.share_link};
});
var langs = [];
for (var lang in languages)
if (languages.hasOwnProperty(lang))
langs.push(languages[lang]);
langs.sort(function (a, b) {
if (a.lang > b.lang) return 1;
if (a.lang < b.lang) return -1;
return 0;
});
for (var i = 0; i < langs.length; ++i)
{
var language = jQuery("#language-template").html();
var lang = langs[i];
language = language.replace("{{LANGUAGE}}", lang.lang)
.replace("{{NAME}}", lang.user)
.replace("{{SIZE}}", lang.size)
.replace("{{LINK}}", lang.link);
language = jQuery(language);
jQuery("#languages").append(language);
}
}body { text-align: left !important}
#answer-list {
padding: 10px;
width: 50%;
float: left;
}
#language-list {
padding: 10px;
width: 50%px;
float: left;
}
table thead {
font-weight: bold;
}
table td {
padding: 5px;
}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b">
<div id="answer-list">
<h2>Leaderboard</h2>
<table class="answer-list">
<thead>
<tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr>
</thead>
<tbody id="answers">
</tbody>
</table>
</div>
<div id="language-list">
<h2>Winners by Language</h2>
<table class="language-list">
<thead>
<tr><td>Language</td><td>User</td><td>Score</td></tr>
</thead>
<tbody id="languages">
</tbody>
</table>
</div>
<table style="display: none">
<tbody id="answer-template">
<tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
<table style="display: none">
<tbody id="language-template">
<tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
0.7734para Olá ou iria.7734ser aceitável?0.7734é obrigatóriooligorequer um zero à direita após o decimal:0.6170Respostas:
CJam,
4442 bytesExperimente online no intérprete CJam .
Para executar o programa na linha de comando, faça o download do interpretador Java e execute:
Como funciona
fonte
Bash + coreutils, 54
Mais uma vez, obrigado a @TobySpeight pela ajuda no golfe.
A lista de palavras de entrada é retirada de STDIN:
fonte
Python 2,
271216211205 bytesEsta é a única idéia que tive até agora. Atualizarei isso assim que pensar em outra coisa! Presumi que precisávamos ler de um arquivo, mas, se não, deixe-me saber para que eu possa atualizar :)
Muito obrigado a Dennis por me salvar 55 bytes :)
Também obrigado ao Sp3000 por salvar 6 bytes :)
fonte
"oizehsglb".index(b)mais curto?d[b] == "oizehsglb".index(b). Possivelmente sem elenco para string / personagem..findé menor que.index, 2) Dependendo da versão que você possui, pelo menos no 2.7.10opensem um argumento de modo padrãor, 3) Nãofor x in open(...)funciona? (pode ser necessário remover uma nova linha à direita) Se não o fizer,.split('\n')será menor que.splitlines()g+=[['0.'+c[1:],c][c[0]!='0']]*c.isdigit(), você pode economizar um pouco mais, revertendofe fazendo, emfor c in fvez de terc=x[::-1]. Além disso, você só usafuma vez, para que você não precisa salvá-lo como uma variávelJavaScript (ES7), 73 bytes
Isso pode ser feito no ES7 apenas 73 bytes:
Ungolfed:
Uso:
Função:
Eu executei isso na lista de palavras UNIX e coloquei os resultados em uma lixeira:
Resultados
O código usado para obter os resultados no Firefox :
fonte
t('Impossible')?Python 2, 121 bytes
Supõe que o arquivo do dicionário
w.txttermine com uma nova linha à direita e não tenha linhas vazias.fonte
GNU sed, 82
(incluindo 1 para
-r)Obrigado a @TobySpeight pela ajuda no golfe.
A lista de palavras de entrada é retirada de STDIN:
fonte
TI-BASIC,
7588 byteseditar 2: não importa, isso ainda é tecnicamente inválido, pois aceita apenas uma palavra por vez (não um dicionário). Vou tentar corrigi-lo para permitir mais de uma palavra como entrada ...
edit: oops; Eu originalmente fiz mostrar um 0 no final se o último número fosse 0, e não o contrário. Corrigido, embora essa seja uma solução alternativa ruim (exibe "0" ao lado do número se começar com 0, caso contrário, exibe dois espaços no mesmo local). No lado positivo, ele manipula corretamente palavras como "Otto" (exibe os dois 0s), pois na verdade não está exibindo um número decimal!
Não consigo pensar em um idioma melhor para fazer isso. Definitivamente, posso jogar mais, mas estou cansado demais agora. O til é o símbolo de negação [o ( - )botão].
A entrada é retirada da variável de resposta da calculadora, ou seja, o que foi avaliado pela última vez (como
_no shell interativo do python), para que você tenha que digitar uma string na tela inicial (as aspas estão ativadas ALPHA+), pressione e ENTER, em seguida, execute o programa. Como alternativa, você pode usar dois pontos para separar comandos; portanto, se você nomear o programa, diga "CALCTEXT" e quiser executá-lo na cadeia "HELLO", poderá digitar em"HELLO":prgmCALCTEXTvez de executá- los separadamente.fonte
Python 2,
147158156 bytesEstava faltando esse '0'. requerimento. Espero que agora funcione bem.
edit : Removido ".readlines ()" e ainda funciona; p
edit2 : Removidos alguns espaços e mova print para a terceira linha
edit3 : salvou 2 bytes graças ao Sp3000 (espaço removido após a impressão e alterado 'index' para 'find')
fonte
Python 2,
184174 bytesfonte
Ruby 2,
8886 bytesA contagem de bytes inclui 2 para as
lnopções na linha de comandos:fonte
==""pode ser substituído por<?A. E não há necessidade degsub()comosub()é suficiente.C,
182172169/181172 bytesExpandido
usando as palavras vinculadas.txt, com conversão em minúsculas:
fonte
*s|32funcionará como conversão em minúsculas nesse contexto?Haskell, 175 bytes sem importações (229 bytes com importações)
Código relevante (digamos no Arquivo Calc.hs):
fonte
Java,
208200176 bytesExpandido
Ele sempre adiciona o decimal e, quando inválido, retorna ".". Mas, caso contrário, funciona como deveria. : P
Obrigado @ LegionMammal978!
fonte
;String l=para,l=e=o+para+=.