Recentemente, fiz uma lição de casa em que tive que aprender um modelo para a classificação de 10 dígitos do MNIST. O HW tinha algum código de andaime e eu deveria trabalhar no contexto desse código.
Meu dever de casa funciona / passa nos testes, mas agora estou tentando fazer tudo do zero (minha própria estrutura nn, nenhum código de andaime hw) e estou preso aplicando o grandiente do softmax na etapa backprop e até mesmo pensar o que é o hw o código do andaime pode não estar correto.
O hw me fez usar o que eles chamam de "perda softmax" como o último nó no nn. O que significa que, por algum motivo, eles decidiram unir uma ativação do softmax com a perda de entropia cruzada em um só, em vez de tratar o softmax como uma função de ativação e a entropia cruzada como uma função de perda separada.
A função de perda de hw fica assim (minimamente editada por mim):
class SoftmaxLoss:
"""
A batched softmax loss, used for classification problems.
input[0] (the prediction) = np.array of dims batch_size x 10
input[1] (the truth) = np.array of dims batch_size x 10
"""
@staticmethod
def softmax(input):
exp = np.exp(input - np.max(input, axis=1, keepdims=True))
return exp / np.sum(exp, axis=1, keepdims=True)
@staticmethod
def forward(inputs):
softmax = SoftmaxLoss.softmax(inputs[0])
labels = inputs[1]
return np.mean(-np.sum(labels * np.log(softmax), axis=1))
@staticmethod
def backward(inputs, gradient):
softmax = SoftmaxLoss.softmax(inputs[0])
return [
gradient * (softmax - inputs[1]) / inputs[0].shape[0],
gradient * (-np.log(softmax)) / inputs[0].shape[0]
]
Como você pode ver, em diante ele faz softmax (x) e depois atravessa a perda de entropia.
Mas no backprop, parece fazer apenas a derivada da entropia cruzada e não do softmax. Softmax é deixado como tal.
Também não deve levar a derivada de softmax em relação à entrada para softmax?
Supondo que ele deva levar a derivada do softmax, não tenho certeza de como esse hw realmente passa nos testes ...
Agora, em minha própria implementação, criei nós separados softmax e entropia cruzada, assim (p e t representam predito e verdade):
class SoftMax(NetNode):
def __init__(self, x):
ex = np.exp(x.data - np.max(x.data, axis=1, keepdims=True))
super().__init__(ex / np.sum(ex, axis=1, keepdims=True), x)
def _back(self, x):
g = self.data * (np.eye(self.data.shape[0]) - self.data)
x.g += self.g * g
super()._back()
class LCE(NetNode):
def __init__(self, p, t):
super().__init__(
np.mean(-np.sum(t.data * np.log(p.data), axis=1)),
p, t
)
def _back(self, p, t):
p.g += self.g * (p.data - t.data) / t.data.shape[0]
t.g += self.g * -np.log(p.data) / t.data.shape[0]
super()._back()
Como você pode ver, minha perda de entropia cruzada (LCE) tem a mesma derivada da hw, porque essa é a derivada da própria perda, sem entrar no softmax ainda.
Mas então, eu ainda teria que fazer a derivada do softmax para encadeá-la com a derivada da perda. É aqui que eu fico preso.
Para softmax definido como:
A derivada é geralmente definida como:
Mas preciso de uma derivada que resulte em um tensor do mesmo tamanho da entrada para softmax, neste caso, batch_size x 10. Portanto, não tenho certeza de como o acima deve ser aplicado a apenas 10 componentes, pois implica que eu diferenciaria todas as entradas em relação a todas as saídas (todas as combinações) ou na forma de matriz.
fonte
Respostas:
Depois de trabalhar mais nisso, descobri que:
A implementação da lição de casa combina o softmax com a perda de entropia cruzada como uma opção, enquanto minha opção de manter o softmax separado como uma função de ativação também é válida.
De fato, a implementação da lição de casa está faltando a derivada do softmax para o passe backprop.
O gradiente do softmax em relação a suas entradas é realmente a parcial de cada saída em relação a cada entrada:
Assim, para a forma vetorial (gradiente):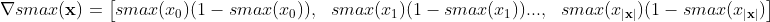
Que no meu código numpy vetorizado é simplesmente:
Onde
self.dataestá o softmax da entrada, previamente calculado a partir do passe para frente.fonte