Acabei de ler sobre o cyclesort através de uma postagem no blog sortvis.org. Esta é provavelmente a mais obscura que eu ouvi até agora, pois usa matemática com a qual não estou familiarizado (detectar ciclos em permutações de conjuntos inteiros).
Qual é o mais obscuro que você conhece?
algorithms
sorting
sova
fonte
fonte
Respostas:
Já ouviu falar em classificação de paciência ? Bem, agora você tem ...
fonte
O Slowsort trabalha multiplicando e se rendendo (ao contrário de dividir e conquistar). É interessante porque é comprovadamente o algoritmo de classificação menos eficiente que pode ser construído (assintoticamente e com a restrição de que esse algoritmo, apesar de lento, ainda deve estar sempre trabalhando em busca de um resultado).
Isso o compara ao bogosort porque, na melhor das hipóteses, o bogosort é bastante eficiente - ou seja, quando a matriz já está classificada. O Slowsort não "sofre" com um comportamento tão bom assim. Mesmo no melhor dos casos, ele ainda tem tempo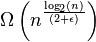 de execução para ϵ > 0.
de execução para ϵ > 0.
Aqui está seu pseudocódigo, adaptado do artigo alemão da Wikipedia :
fonte
Não sei se isso é obscuro, mas um dos "algoritmos" de classificação mais ridículos é o Bogosort . Os links da página Bogosort também são divertidos.
E há esta jóia da seção "quantum bogo-sort".
Hummm ... você poderia dizer isso :-).
fonte
Outro "algoritmo" obscuro é o Intelligent Design Sort - mas nenhum algoritmo é mais rápido ou tem menos consumo de memória :)
fonte
Tipo de sono é bastante novo.
fonte
Eu acho que o tipo de bolha também seria a resposta errada nessa situação
:)
fonte
O Knuth Volume 3 1 , na resposta a um dos exercícios, fornece uma implementação de um algoritmo de classificação sem nome que é basicamente um código antigo de golfe - o tipo mais curto que você pode escrever na linguagem assembly MIX. O código curto vem com o preço muito menor da complexidade de O (N 3 ) embora ...
1 Pelo menos nas edições mais antigas. Dadas as modificações no MIXAL para a nova edição, não tenho certeza se ele ainda está lá, ou faz algum sentido minúsculo no MIXAL original.
fonte
Para minha classe de estruturas de dados, eu tive que (explicitamente) provar a correção do tipo Stooge . Tem um tempo de execução de O (n ^ {log 3 / log 1.5}) = O (n ^ 2.7095 ...).
fonte
Não sei se é o mais obscuro, mas o tipo de espaguete é um dos melhores em situações em que você pode usá-lo.
fonte
Um dos livros originais de Knuth, "Sorting and Searching", tinha uma dobra no meio que mostrava um processo que classificava um arquivo de fita sem disco rígido. Eu acho que ele usou seis unidades de fita e mostrou explicitamente quando cada uma estava sendo lida para a frente, lida para trás, rebobinando ou ociosa. Hoje é um monumento a uma tecnologia obsoleta.
fonte
Certa vez, fiz um tipo de bolha de registradores vetoriais no assembler CRAY. A máquina possuía uma instrução de turno duplo, que permitia alterar o conteúdo de um registro de vetor para cima / baixo em uma palavra. Coloque todos os outros pontos em dois registros vetoriais, para que você possa fazer uma classificação completa de bolhas sem precisar fazer outra referência de memória até terminar. Exceto pela natureza N ** 2 do tipo de bolha, foi eficiente.
Também precisei fazer um tipo de ponto flutuante de um vetor de comprimento 4 o mais rápido possível para um único tipo. Fiz isso através da pesquisa de tabela (o bit de sinal de A2-A1 é um bit, o sinal de A3-A1 forma outro bit ..., então você olha o vetor de permutação em uma tabela. Na verdade, era a solução mais rápida que eu poderia encontrar Porém, não funciona bem em arquiteturas modernas, as unidades flutuantes e as inteiras são muito separadas.
fonte
O Google Code Jam teve um problema com um algoritmo chamado Gorosort, que acho que eles inventaram para o problema.
http://code.google.com/codejam/contest/dashboard?c=975485#s=p3
fonte
Não lembro o nome, mas era basicamente
fonte
Classificação do shell
Talvez o próprio algoritmo não seja tão obscuro, mas quem pode nomear uma implementação que é realmente usada na prática? Eu posso!
O TIGCC (um compilador baseado em GCC para calculadoras gráficas TI-89/92 / V200) usa a classificação Shell para a
qsortimplementação em sua biblioteca padrão:A classificação do shell foi escolhida em favor do quicksort para manter o tamanho do código baixo. Embora sua complexidade assintótica seja pior, a TI-89 não possui muita RAM (190K, menos o tamanho do programa e o tamanho total de qualquer variável não arquivada), portanto, é um pouco seguro assumir que o número de itens será abaixo.
Uma implementação mais rápida foi escrita depois que eu reclamei sobre ser muito lenta em um programa que eu estava escrevendo. Ele usa melhores tamanhos de espaço, além de otimizações de montagem. Pode ser encontrado aqui: qsort.c
fonte