Essa questão surge da minha confusão real sobre como decidir se um modelo logístico é bom o suficiente. Eu tenho modelos que usam o estado dos pares de projetos individuais dois anos após serem formados como uma variável dependente. O resultado é bem-sucedido (1) ou não (0). Eu tenho variáveis independentes medidas no momento da formação dos pares. Meu objetivo é testar se uma variável, que eu imaginei, influenciaria o sucesso dos pares, afeta esse sucesso, controlando outras influências em potencial. Nos modelos, a variável de interesse é significativa.
Os modelos foram estimados usando a glm()função in R. Para avaliar a qualidade dos modelos, eu fiz algumas coisas: glm()fornece o residual deviance, o AICe o BICpor padrão. Além disso, calculei a taxa de erro do modelo e plotei os resíduos binados.
- O modelo completo possui um desvio residual menor, AIC e BIC do que os outros modelos que eu estimei (e que estão aninhados no modelo completo), o que me leva a pensar que esse modelo é "melhor" que os outros.
- A taxa de erro do modelo é bastante baixa, IMHO (como em Gelman e Hill, 2007, pp.99 ):
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)em torno de 20%.
Por enquanto, tudo bem. Porém, quando planto o resíduo acumulado (novamente seguindo o conselho de Gelman e Hill), grande parte das caixas fica fora do IC 95%:
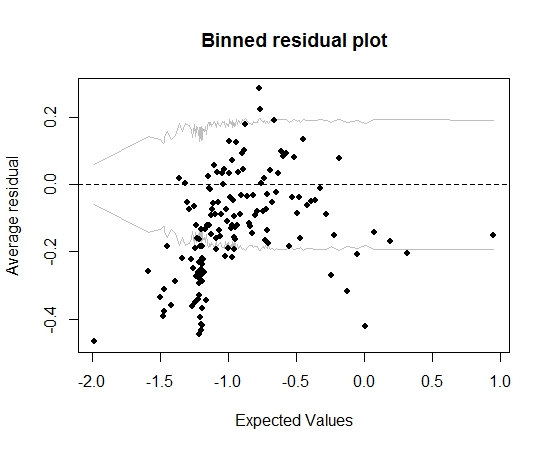
Esse enredo me leva a pensar que há algo totalmente errado no modelo. Isso deveria me levar a jogar fora o modelo? Devo reconhecer que o modelo é imperfeito, mas mantê-lo e interpretar o efeito da variável de interesse? Eu brinquei com a exclusão de variáveis, por sua vez, e também com algumas transformações, sem realmente melhorar o gráfico de resíduos binados.
Editar:
- No momento, o modelo possui uma dúzia de preditores e 5 efeitos de interação.
- Os pares são "relativamente" independentes um do outro, no sentido de que todos são formados durante um curto período de tempo (mas não estritamente falando, todos simultaneamente) e há muitos projetos (13k) e muitos indivíduos (19k ), portanto, uma proporção justa de projetos é unida por apenas um indivíduo (existem cerca de 20.000 pares).
fonte
Respostas:
A precisão da classificação (taxa de erro) é uma regra de pontuação inadequada (otimizada por um modelo falso), arbitrária, descontínua e fácil de manipular. Não é necessário neste contexto.
Você não indicou quantos preditores havia. Em vez de avaliar o ajuste do modelo, ficaria tentado a ajustá-lo. Uma abordagem de compromisso é assumir que as interações não são importantes e permitir que preditores contínuos não sejam lineares usando splines de regressão. Traçar os relacionamentos estimados. O
rmspacote em R torna tudo isso relativamente fácil. Veja http://biostat.mc.vanderbilt.edu/rms para mais informações.Você pode elaborar "pares" e se suas observações são independentes.
fonte
A situação parece um pouco estranha, mas acho que seu enredo pode fornecer uma pista. Parece que pode haver um relacionamento curvilíneo. É permitido usar termos polinomiais e outras transformações de variáveis preditoras (por exemplo,x2 ) na regressão logística, assim como na regressão OLS. Vale a pena tentar.
fonte