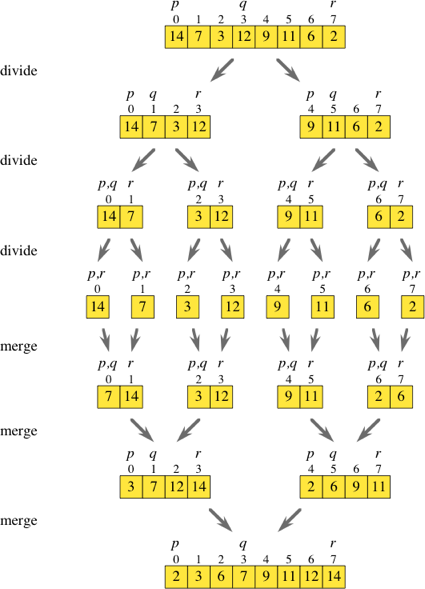
Portanto, a classificação por mesclagem é um algoritmo de divisão e conquista. Enquanto eu observava o diagrama acima, estava pensando se era possível ignorar basicamente todas as etapas de divisão.
Se você iterou sobre a matriz original enquanto pulava duas vezes, poderia obter os elementos no índice iei + 1 e colocá-los em suas próprias matrizes ordenadas. Depois de ter todas essas sub-matrizes ([7,14], [3,12], [9,11] e [2,6], como mostrado no diagrama), você pode simplesmente prosseguir com a rotina de mesclagem normal para obter uma matriz classificada.
A iteração na matriz e a geração imediata das sub-matrizes necessárias são menos eficientes do que as etapas de divisão na sua totalidade?
algorithms
sorting
efficiency
mergesort
Jimmy_Rustle
fonte
fonte
Respostas:
A confusão surge da diferença entre a descrição conceitual do algoritmo e sua implementação .
A classificação de mesclagem lógica é descrita como dividir a matriz em matrizes menores e depois mesclá-las novamente. No entanto, "dividir a matriz" não implica "criar uma matriz inteiramente nova na memória" ou algo assim - poderia ser implementado no código como
isto é, nenhum trabalho real ocorre e a "divisão" é puramente conceitual. Portanto, o que você sugere certamente funciona, mas logicamente você ainda está "dividindo" as matrizes - você não precisa de nenhum trabalho do computador para fazê-lo :-)
fonte
1<<n+1. Embora eu tenha certeza de que você pode ajustar as coisas para que uma cauda muito pequena seja mesclada em um passe mais baixo.Eu acho que você quer dizer com implementação de baixo para cima . Na implementação de baixo para cima, você inicia com elementos de célula única e move-se para cima, mesclando elementos em listas / matrizes maiores. Basta inverter as setas da figura acima, começando na matriz do meio, ou seja, matrizes de um elemento.
Além disso, convém otimizar a classificação de mesclagem dividindo matrizes até que elas atinjam um tamanho constante, após o qual você simplesmente as classifica usando, por exemplo, classificação de inserção.
Caso contrário, a classificação sem dividir a matriz não é possível. De fato, a essência da classificação Merge é dividir e classificar os sub-arranjos, isto é, dividir e conquistar.
fonte